「英検®1級の単語なんて、実生活ではまず使わない」「結局は記憶力勝負。才能がない人間には無理だ」

もしあなたがそう感じているのなら、それは自然なことです。英検®1級の語彙問題は、日常会話の延長ではなく、知的活動のための英語を前提に設計されており、知的議論の場で扱われる高度に抽象的な概念を、英語で正確に処理できるかを測定する試験だからです。
実際に英語の高級誌(The Economist など)を読んでみれば、1級レベルの語彙など珍しいものではありません。逆に言えば、これらの語彙を知らないと、そのレベルの知的活動を英語でこなすことはできないということです。とはいえ、非英語ネイティブにとっては、これらの語彙の攻略は確かに高い壁です。
しかし、この高すぎる壁の攻略こそが、実は英検®1級合格への最短ルートだとすればどうでしょうか?

この記事で公開するメソッドは、単に「英検®1級に受かるためのテクニック」に留まりません。準1級や2級を目指す方はもちろん、語彙力の伸び悩みに直面しているすべての英語学習者にとって、一生モノの武器となる英単語暗記法です。
多くの人が陥る「書いて覚える」「根性で繰り返す」といった非効率な学習から卒業し、脳の仕組みをハックした忘れたくても忘れられない学習デザインを手に入れてください。
一度コツを掴めば、英検、TOEIC、そしてその先にある実務や留学先での語彙習得スピードが劇的に変わります。本気で英語を武器にしたいすべての方へ。このロードマップが、あなたの学習効率を「一生更新し続ける」きっかけになるはずです。

英語専門オンライン個別指導エイゴメンターズ主宰|大手オンラインスクール元講師|英検1級語彙セクション満点|東京大学大学院修了
独学で英語を極めたい受験生のために、本質的な学習法を発信中。根拠に基づいた指導で、短期間でのスコアアップを実現します。
戦略的な学習デザインで英検®1級語彙を完全攻略
語彙は、最も投資対効果が高いセクション
英検®1級は日本の英語資格における一つの到達点ですが、構造を冷静に分析すれば、語彙セクションほど努力が得点に直結する「投資対効果の高い領域」はありません。
多くの受験者は全セクションを平均的に対策しようとしますが、それは運の要素を孕む危うい戦略です。
- 読解・リスニング:話題との相性や当日の集中力によってスコアが大きく変動する
- 語彙(新形式22問):「知っているか、知らないか」で決まり、試験当日の運要素が極めて入り込みにくい最大の安定得点源
試験開始直後の10分で語彙22問を取り切る。そこで大きなリードを確保し、精神的余裕を持って残りのリーディングやライティングに臨む。これが、私が提唱する英検®1級における「戦わずして勝つ」戦略です。
3回連続で証明された才能を不要にする学習デザイン
私自身、特別な記憶力を持っているわけではありません。しかし、才能に依存しない学習設計を構築した結果、過去3回の英検®1級1次試験において以下のスコアを叩き出しています。
- 2025年度第1回 ▶︎ 22/22
- 2025年度第2回 ▶︎ 21/22
- 2025年度第3回 ▶︎ 21/22
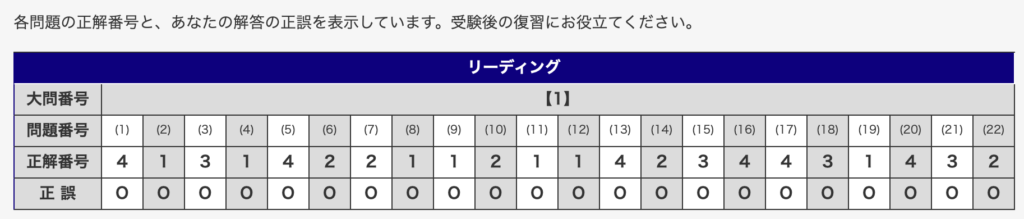
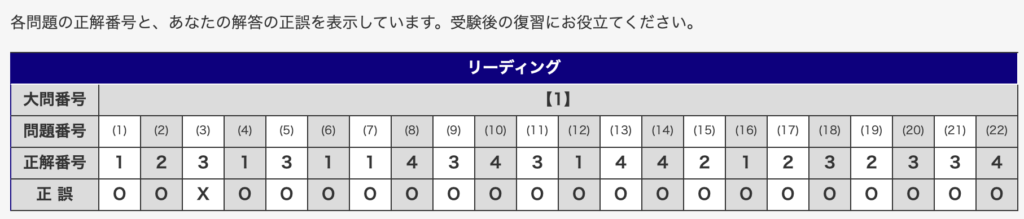
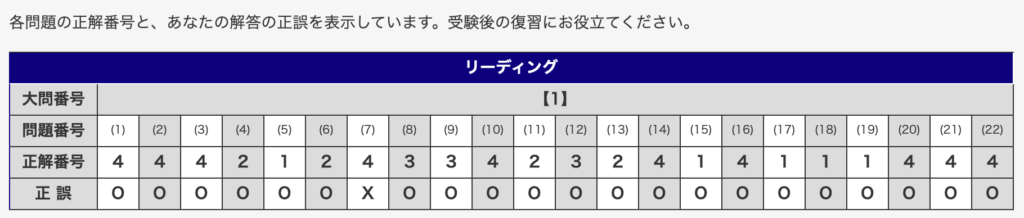
わずか57日間の対策で英検®1級語彙セクション満点を奪取し、その後も95%以上の正答率を維持し続けています。この結果は、単純暗記だけに頼らない学習を実践できたからこそ達成できたものです。
個々の語彙を孤立した暗記対象として扱うのをやめ、
- 【戦略】選択と集中|出題傾向の分析からターゲット語彙を徹底的に絞り込み、習得度に応じて学習優先度を決定
- 【戦術】概念接続|概念の直接リンクによる英語回路の高速化/語彙ネットワーク・クラスターの構築による記憶の長期化
- 【実行】科学的グリッド|忘却曲線から逆算した復習スケジュール
この3点を統合した結果、本番では22問中22問の満点を達成しました。(その後、連続で1ミスしているのは許してください笑)
本記事では、私が実際に用いた英検®1級語彙完全攻略ロードマップを、誰でも再現できる形で体系化しています。
- 「英→日」翻訳を脱却し、意味をイメージや文脈リンクで定着させる手法
- AIを活用しながら、未知語を接辞・語源をもとに連鎖的に紐づけるネットワーク暗記法
- 忘れることを前提とした、科学的で現実的な反復スケジューリング
これらは根性論ではありません。英検®1級という試験を、才能勝負にしないための仕組みです。
正しく学習を設計すれば、この壁は短期間で、しかも高い再現性を持って突破できます。
【戦略編】戦う前に詰みの盤面を作る
学習をスタートさせる前に、最も重要な工程がひとつあります。それは「頑張ること」でも「気合を入れること」でもありません。
どの戦場で、どの武器を使って戦うかを決めること(選択と集中)。言い換えれば、リソース配分の最適化です。
英検1級の語彙範囲(10000〜15000語)は広大です。この範囲を、無計画に、均等な力配分で歩き回るのは最悪の選択です。まずやるべきは、全体を俯瞰し、境界線を引くこと。戦う場所と、戦わない場所を明確に分けるところから、戦略は始まります。
教材選定:デジタルな網羅性とアナログな質感のハイブリッド
私が採用したのは、アプリと紙の教材を役割分担させる戦略です。目的はシンプルで、「必要な語彙は漏れなく網羅し、定着は深く」。この両立を、最小の労力で実現するための構成です。
英検®1級 でた単(アプリ):過去問データの集積地
「でた単」シリーズの最大の価値は、過去に出題された語彙が、ほぼ完全に集約されている点にあります。でた単1級の見出し語は5,000語以上ありますが、その価値の本質は頻度順で学習できるという設計にあります。
英検®1級語彙問題の出題は完全にランダムに決まってはいません。出題には明確な偏りがあり、高頻度語彙が出題の大半を占めます。だから、全範囲を同じ精度で追う必要はありません。まずは上位約3,000語(句動詞を含む)。このゾーンを押さえるだけで、統計的には満点に近い得点が視野に入ることがわかっています。
出る順で最短合格!英検®1級単熟語EX 第2版(紙):思考を整理するメインウェポン
一方で、定着の主戦場は紙です。アプリは隙間時間の確認には向いていますが、語彙を意味・用法・ニュアンスまで含めて脳に固定するには限界があります。
紙には学習効率を底上げする以下の特性があります。
- 書き込みができる
- 一覧性がある
- 進捗が物理的に残る
数ある教材の中でも「出る順で最短合格!英検®1級単熟語EX 第2版」は、近年の出題傾向と最も整合的です。この一冊の見出し語を完璧に仕上げる。それ自体が、合格への最短経路になります。
3,000語が急所である理由
ここで誤解してほしくない点があります。これは「網羅よりも精度」という話ではありません。網羅性は維持した上で、根拠をもって「捨てる部分」を決め、残した範囲の暗記精度を極限まで高める。この取捨選択と精度向上の両輪が重要なのです。
未知の5,000語を50%の精度で覚えるよりも、厳選した3,000語を100%の精度で叩き込む。限られた期間で合格点を取りに行く以上、これは努力論ではなく、期待値マネジメントの問題です。
戦略目標の画定
ここで設定する戦略目標は、明確です。
「でた単 × EX」を使い、高頻度語彙3,000語を完璧にする。
言い換えるなら、「EXの見出し語を、日本語を介さずに反射的に理解できる状態まで仕上げること」です。
この盤面が完成した瞬間、語彙問題はただの運試しではなくなります。勝敗は、試験当日ではなく、この学習設計の段階ですでにほぼ決まっている。そう言っても過言ではありません。
【戦術編 ①|第1〜2フェーズ 】脳内に仕分け棚を作る
戦略が決まったら、次は戦術です。ここで多くの人が同じ失敗をします。
いきなり「暗記」に突き進んでしまうこと。
まだ覚える段階ではありません。まず必要なのは、覚える対象を整理し、単語を脳内に定着させるための器を用意することです。
この章では、そのための準備工程を扱います。
【第1フェーズ】既知と未知の仕分けから始める
限られた時間の中で、すでに知っている単語を何度も眺めるのは、純粋なリソースの浪費です。
まず行うのは、現在地の把握。言い換えれば、語彙の品定めです。
◯△マーキング
1級単熟語EXを最初から最後まで通し、各見出し語に対して、瞬間的な判断を下します。
- 意味が即座に出る → ◯(既知語)
- うっすら分かる/推測できる → △
- それ以外 → 無印(未知語)
ここで重要なのは、立ち止まらないこと。反射レベルで判断してください。
余裕があれば、でた単(アプリ)のカード機能などでも仕分け作業をしておくと、その後の学習がスムーズになります。
フォーカスするのは綴りと基本の意味だけ
この段階では、
- 例文
- 派生語
- コロケーション
はすべて無視します。
見るのは、見出し語の綴りと、最も基本的な意味だけ。
未知語が大量に並ぶことに、気後れする必要はありません。それは今後の伸び代そのものだからです。この段階で、チェックした語彙の8割程度が未知語であっても問題ありません。
【第2フェーズ】発音の同期|文字と音をリンクさせる
綴りと基本語義による仕分けが終わったら、次に行うのが発音の確認です。意味暗記の前に、必ずこの工程を挟みます。
音を知らない単語は、脳に残らない
脳にとって、音の伴わない文字列は、ただの記号です。
高頻度3,000語すべてについて、「この単語を正しい音で再生できるか」を確認します。
ここで頼るのは自己判断や雰囲気ではありません。
- 発音記号を見て、音とアクセントが即座に再現できる
- ダウンロード音声を再生し、自分の想定とズレがない
この2点を満たしたものは、確認完了としてそのまま進む。
一方で、
- アクセント位置に迷う
- 母音・子音の処理に違和感がある
こうした単語には 「※発音」 などの印をつけます。
印がついた単語だけ、
- 音声を確認する
- 実際に声に出して真似する
この2ステップを踏みます。この工程を、綴りと基本語義による仕分けとセットでいっきに行います(ここまでのステップでターゲット語彙全体に少なくとも2回ずつ触れたことになります)。
なぜここで厳密さが必要なのか
この段階で音が曖昧なままだと、後の意味暗記フェーズで、
- スペル
- 音
- 意味
が分離したまま記憶され、定着が極端に悪くなります。
逆に、ここで音と綴りが完全に同期した単語は、意味を乗せた瞬間に一気に記憶に固定されます。さらに言えば、リーディングやリスニングでも即座に反応できる認識語彙としての定着可能性が高くなります。
この段階では「覚えようとしない」
意外に思われるかもしれませんが、この段階では、意味を覚える必要はまったくありません。
意味は「見たことがある」程度で十分です。ここでの目的は一貫しています。
単語の意味を脳内に配置するための「器(音とスペル)」を整備すること。
この下地がある状態で意味を入れるのと、何もない状態で暗記するのとでは、学習効率に決定的な差が生まれます。
【戦術編 ②|第3〜4フェーズ 】意味イメージと語彙ネットワークの構築
「音」と「綴り」という器が整ったら、次はいよいよ、その中に意味を流し込んでいきます。
ここで最も重要なのは、多くの学習者が無意識に採用している「英単語→日本語訳」という処理回路から距離を取ることです。日本語を使ってはいけない、という話ではありません。問題は日本語をゴールに据えてしまうことにあります。
【第3フェーズ】英語 → 意味イメージ/文脈リンクの回路を作る
英検1級で問われる語彙の多くは、抽象度が高く、文脈によってニュアンスが変化します。それらを特定の日本語訳に固定して覚えてしまうと、実際の文章の中で意味が揺れた瞬間に、理解が止まります。
概念ラベリング
目指すべき状態はシンプルです。英語を見た瞬間に、その語彙が指し示す具体的な映像、または状況・関係性・動きによって示唆されるイメージが瞬間的に想起できることです。英語を日本語に「翻訳」するのではなく、概念として受け取る感覚が重要です。
少し抽象的な説明になってしまいますが、具体的な映像または文脈によって示唆されるイメージに「英語の文字列や音声」というラベルを貼る感覚です。
日本語の語彙セットが私たちの脳内でどのように定着しているのかを考えてみれば、日本語の文字列や音声以前に、具体的な対象物や状況・関係性・動きといったものによって示唆されるイメージ(文脈)が先にあって、それらに日本語(文字と音声)というラベルを貼り付けて固定しているのではないでしょうか?
表現したい対象を日本語で瞬間的に想起して扱えるのは、この概念ラベリング的な記憶メカニズムが関係しているという仮説がこの学習デザインの裏付けです。
日本語訳の正しい位置づけ
もちろん、英単語の日本語訳が言えるに越したことはありません。ただし、その役割は主役ではなく補助的なものです。正しい理解はこうです。
英単語ラベル ⇄ 意味イメージ(概念)⇄ 日本語訳(日本語ラベル)
日本語は、意味イメージを確認・固定するための「別タグ」にすぎません。この理解をもとに、正しい処理回路を作っておくと、未知の文脈でその単語に出会っても、日本語に頼らず意味を掴めるようになります。
【第4フェーズ】AIの活用:未知語を既知語に結びつける
意味イメージだけで突破できない単語も、当然出てきます。そうした語には、より高度な戦術を用いましょう。ここで投入するのが、以下の2つの武器です。
- 現代最強のツール: 人工知能(AI)
- 古典最強の分析ツール: 接辞と語源
語彙の広がりをネットワークとして扱う
未知語を、孤立した点として覚えないこと。接頭辞・接尾辞・語根をフックに、すでに知っている単語の網に引っ掛けていきます。
- AIの活用: 「この単語と同じ語源を持つ、簡単な単語は?」などと問い、自分の知っている単語と結びつける。
こうして、新しい語を既存の知識構造に接続していきます。
修正する過程も記憶になる
もちろん AI の説明が常に正しいとは限りません(ハルシネーション)。しかし、それで構いません。自分で調べ直し、「なるほど、ここは違うな」「この意味の広がりはこういうことか」と修正するその過程自体が、脳にとって非常に強力な記憶フックになります。
【戦術編 ③ |第5フェーズ】語彙クラスターの形成:バラバラの知識を有機的に結合する
暗記が進むと、一見無関係に見えていた未知語の間にも、共通の要素や意味のまとまりが浮かび上がってきます。この兆候を逃さず、単語を独立した「点」ではなく、有機的なつながりを持つ「ネットワーク」、「群(クラスター)」として再定義することが、爆発的に語彙力を伸ばす鍵となります。
このフェーズでも第4フェーズと同様に AI を学習補助として積極的に活用していきましょう。本セクションでは、AI をうまく活用するためのプロンプト(AIへの指示文)の例も紹介するのでそちらも参考にしてください。
接辞+語源(語根)による垂直結合
まずは、共通の「語源(語根)」を持つ単語を芋づる式にまとめます。
- 例:voke(呼ぶ・声を出す)
- invoke(in- 中に + voke 呼ぶ|法を発動する・神などに祈る)
- revoke(re- 後ろへ/否定 + voke 呼ぶ|取り消す・無効にする)
- provoke(pro- 前方に + voke 呼ぶ|引き起こす・挑発する)
- convoke(con- 共に + voke 呼ぶ|会議などを招集する)
漢字の「へん」や「つくり」を覚える感覚で共通項を括り出すと、1つの語源が複数の単語を支える強力な支柱に変わります。
ここでは共通の語根 -voke- に異なる接頭辞が付加されることによって、語彙のネットワークが形成されています。
意味の近さによる水平結合
語根が異なる場合でも、「意味の近さ」を基準に対比させることで、新たな語彙ネットワークが形成できます。
- 例:「集まる」を攻略する convoke と convene
- convoke(招集する): con(共に)+ voke(呼ぶ|voice 声)。リーダーが「集まれ!」と声をかけて呼び寄せる、公的・強制的なイメージ。
- convene(開催される・集まる): con(共に)+ vene(来る|come)。人々が自ら一箇所へ向かって「来る」というイメージ。
- ネットワークの拡張: vene(来る)を理解すれば、venue(人々が来る場所=開催地)や intervene(inter- 間に + vene 来る=介入する)も、パズルを解くように芋づる式に理解できます。
場面・トピックによる多次元的な結合
さらに、特定のトピック(政治、医療、心理学など)で頻出する語彙を空間的にまとめます。
- 例:「選挙・政治」クラスター
- constituency(選挙区)、gerrymandering(選挙区の不正操作)、incumbent(現職の)
参考 AI プロンプト|「点」から「面」、そして「空間」へ
単語が独立した知識(点)のままだと、脳はそれを「不要な情報」と判断し、すぐに忘却の彼方へ追いやってしまいます。
しかし、これらをネットワーク(面)やクラスター(空間)の一部として組み込むと、どれか一つを思い出せば、連鎖的に他の語が引き出される無敵の状態が生まれます。
未知の語彙が、バラバラに分離した「異物状態」から、有機的に連結された「構造物」へと変わる瞬間。これこそが、才能に頼らず語彙力をブーストさせ、英検®1級という壁を再現性高く突破するための真髄なのです。
最後に参考プロンプト(AI への指示文)を紹介します。適宜修正しながら、英単語学習に AI をうまく活用してみましょう。
Role
あなたは世界最高峰の英語言語学者、および英検1級満点取得者を多数輩出している超一流英語コーチです。私の語彙学習をサポートするために、指定された単語を単なる暗記対象(点)ではなく、記憶に深く根を張る「有機的なネットワーク/クラスター」として構造化して解説してください。
Task
入力された英単語について、以下の5つのセクションで出力してください。
- 【Core: 語源の解剖と物理イメージ】
単語を「接頭辞・語根・接尾辞」に分解し、それぞれの原義を明示してください。その上で、それらが組み合わさってなぜその意味になるのか、脳裏に浮かぶ「物理的な動きやイメージ」を比喩を用いて解説してください。※一般的な日本語の訳語も併記すること。- 【Vertical: 語源ファミリー(垂直展開:面)】
同じ語根を持つ重要な関連語を3〜5つ厳選してください。各単語について「接頭辞+語根+接尾辞」の構成を解剖し、コアとなる意味が接頭辞の方向性によってどう派生したかを論理的に説明してください。※各単語に日本語訳を併記すること。- 【Horizontal: 概念クラスター(水平比較:面)】
語源は異なるが、意味が近い類義語を1〜2つ挙げ、その「微細なニュアンスの境界線」を明確にしてください。特に「物理的イメージの差(例:声で呼ぶのか、足で来るのか)」や「強度の違い」に焦点を当てて比較してください。※各単語に日本語訳を併記すること。- 【Multidimensional: 場面・トピック結合(空間)】
その単語が「どの場面・トピックの空間(例:政治、法、学術、心理学など)」に所属しているかを明示してください。そのトピック内で共に使われやすい関連語を3〜5語(クラスター語彙)頻出例文と共に提示し、背景知識を加えることで、立体的な記憶の定着を図ってください。- 【Context: 知的活動への応用(実践)】
英検1級の二次試験(スピーチ)や The Economist 誌の社説でそのまま使えるような、格調高く自然な例文を1つ提示してください。単語のコロケーション(相性の良い語との繋がり)が際立つ文章にしてください。Output Style
- 専門的でありながら、学習者の知的好奇心を刺激する情熱的なトーンで。
- 箇条書きや太字を活用し、一目で構造(面と空間)がわかるように。
Input Target
【ここに対象となる英単語を入力してください】
【実行編|第6〜7フェーズ】科学的グリッドでやり抜く|忘却曲線を物量で踏みつぶせ
どれほど精巧な設計図(ネットワーク)を描いても、それを脳に定着させるには、最後は「物量」という名の暴力が必要です。
ただし、その物量の使い道を間違えてはいけません。ただ眺めるだけの単純反復だけでは学習効率が悪いです。投下するリソースを、いかにして最大の定着効率に変換するか。その具体的な方法を解説します。
【第6フェーズ】リトリーバル学習と分散学習
脳を効率よく書き換えるには、認知科学における二つの最強の武器、リトリーバル学習(想起)と分散学習を正しく運用する必要があります。
リトリーバル学習:脳に負荷をかけて想起する
単語帳を「眺める」のは効率の良い学習ではありません。思い出す(リトリーバル)ことこそが学習の本質です。
- テスト形式を徹底する:意味を確認する前に、1秒でいいので「この単語のイメージは何だったか?どのような文脈で使われたか?どんな単語と一緒に使われたか?」などと記憶を芋づる式に想起し、脳に負荷をかけます。
- アウトプットの瞬間に定着する:脳は情報を入れた時ではなく、引き出そうと試行錯誤した瞬間に、その回路を太くします。第3〜5フェーズの意味イメージや語彙ネットワーク/クラスターを思い出す負荷を、毎回の周回で自分に課してください。
分散学習:1日の上限設定と復習間隔のコントロール
物量でゴリおす場合には、自分の限界値をしっかりと見極めながら継続できる最大負荷をかけるようにしましょう。
- 1日の集中上限|500 語を目安にする:1日に「新規学習・および集中的な復習」として扱うのは、まずは500語を一つの目安にしてください。これを超えると、一つひとつの想起の質が下がり、作業が「ただページをめくるだけ」の形骸化したものになりやすいためです。(経験則)
- 自分自身の「限界値」を検証せよ:ただし、500語は絶対的な正解ではありません。人によって、あるいは習熟度によって、最適な負荷は異なります。「300語を超えると想起の精度が落ちる」のか、「今の自分なら700語までは高い集中力を維持できる」のか。自分自身の脳が発するサインを冷静に観測し、継続可能な最大負荷を検証し続けてください。 重要なのは、設定した語数をこなすことではなく、その語数すべてに質の高い想起を伴わせることです。
- 復習サイクルの拡大(分散学習 spaced repetition):その日の「集中枠」に入らない語彙は、あえて「間隔を置いて」配置します。定着度に応じて、1日後、3日後、1週間後、2週間後……と、復習の間隔を次第に広げていきます。このような復習サイクルの効果はさまざまな研究でその有効性が実証されています。
【第7フェーズ】使えるものは何でも使おう
どれほど論理的にネットワークを組んでも、どうしても指の間からこぼれ落ちた苦手な語彙が残ります。ここまで来ると、理屈を超えた執念が必要です。
- こじつけの美学:語呂合わせ、似た音の日本語との紐付け、理不尽な(?)印象付け。時にはこじつけという名の無理矢理戦法で脳に叩き込みます。不思議なことに、その「こじつけ」自体は忘れてしまっても、意味イメージだけが脳に残る段階がやってきます。(たぶんね…)
- 徹底した優先順位付け:忘れない確信が持てたら ◎ をつけて復習頻度を落とす。未定着の語彙だけにリソースを集中投下することで、周回速度を極限まで高めていきます。
【実践テスト】「英語→意味イメージ」の高速回路を検証する
仕上げは、過去問と予想問題による実践です。目安として20セット以上の演習を積みます。
- 日本語を介さない読解:回路が完成していれば、選択肢を見た瞬間に、文脈に適合する「意味イメージ」が浮き上がります。この段階で9割以上の正答率が安定していれば、語彙問題は「ボーナスステージ」に変わります。
- 学習時間の目安:準1級程度の土台があれば、180〜240時間(毎日3〜4時間を2ヶ月)が一つの目安です。短期間に高密度で走り抜ける方が、認識語彙の習得効率は圧倒的に高まります。苦手意識が強い場合には、この目安の2倍の時間を見積もってください。【私の記録|でた単アプリで140時間前後+EXが約75時間 ※記録もれもあると思うのでもう少しやっているかも】
- メンテナンス:一通りの学習が終了し、9割以上の完成度に到達したら、徐々に復習頻度を減らしてメンテナンスモードに入りましょう(1ヶ月以上放置しても10〜20時間くらいの復習で9割戻せる)。ここまで来れば、リーディング・リスニング・ライティングおよびスピーキングの個別攻略が優先課題になっているはずです。
結びに代えて:英検1級は通過点
ここまで読み進めたあなたなら、もう気づいているはずです。
もはや英検1級語彙は、攻略不可能な高い壁などではありません。正しく学習を設計し、正しい負荷をかけて学習を継続すれば恐れることはありません。
この学習デザインの通りに走り抜けた先には、満点というスコア以上のものが待っています。それは、ネイティブが読むニュースや論文を、高い解像度で読み解けるようになるというご褒美です。もちろん、分野によっては英検1級以上の語彙も登場しますが、以前に比べれば辞書を紐解く機会は劇的に減っているはずです。
英検1級の勉強はきっかけにすぎません。さあ、今この瞬間から始めましょう。